- Published on
浏览器基础
- Authors

- Name
- 游戏人生
渲染流程
浏览器输入url后经历的过程
- 首先,在浏览器地址栏中输入url
- 浏览器先查看浏览器缓存-系统缓存-路由器缓存,如果缓存中有,会直接在屏幕中显示页面内容。若没有,则跳到第三步操作
- 在发送 http 请求前,需要域名解析(DNS寻址),解析获取相应的IP地址
- 浏览器向服务器发起 tcp 连接,与浏览器建立TCP三次握手
- 握手成功后,浏览器向 web 服务器发送HTTP请求,请求数据包
- 服务器处理收到的请求,并返回HTTP响应
- 四次挥手,释放TCP连接
- 浏览器收到HTTP响应,读取页面内容,浏览器渲染,解析html源码
- 生成Dom树、解析css样式、js交互
寻址过程
DNS概念
因特网上作为域名和 IP地址 相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的 IP 数串。通过主机名,最终得到该主机名对应的 IP地址 的过程叫做域名解析(或主机名解析)。
DNS寻址过程
- 浏览器从 DNS 缓存文件中查找域名对应的IP,如果没有,进行下一步
- 从操作系统的缓存文件(hosts)中查找,如果没有,进行下一步
- 从本地域名服务器进行查找,如果没有,进行下一步
- 使用递归查询或者迭代查询,从根域名服务器开始查找
- 本地服务器查询到域名的IP地址后,就返回浏览器进行缓存并开始建立TCP链接
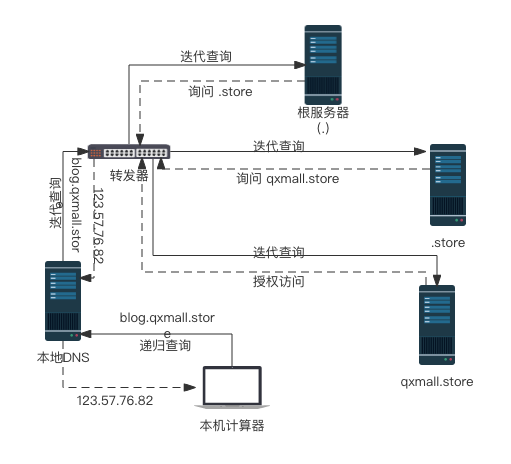
递归查询
- 本地域名服务器向根域名服务器发送查询请求
- 根域名服务器向顶级域名服务器发送查询请求
- 顶级域名服务器向权威域名服务器发送查询请求
- 若某一个环节查到,则会进行缓存且按照查询的路径返回
迭代查询
- 本地域名服务器会先向根域名服务器发送请求获取顶级域名服务器地址
- 本地域名服务器向顶级域名服务器发送DNS解析请求,顶级域名服务器返回权威域名服务器地址
- 本地域名服务器向权威域名服务器地址发送DNS解析请求,获取到域名的IP地址
文档解析
构建DOM树
- 从请求的 HTML 文档中读取到文档字符串
- 将文档字符串转换为Token(词语),每一个标签代码都会被转成一个Token对象(Token对象的生成是通过元素标签的开始标签和结束标签判断的,根据子节点标签是否在父节点开始和结束标签之间来判断父子关系)
- 当一个 Token 对象产生后,会立即通过该 Token 对象创建DOM节点对象,同时会继续生成新的Token对象
- 当所有的DOM节点创建完成后即形成了DOM树
流程图如下
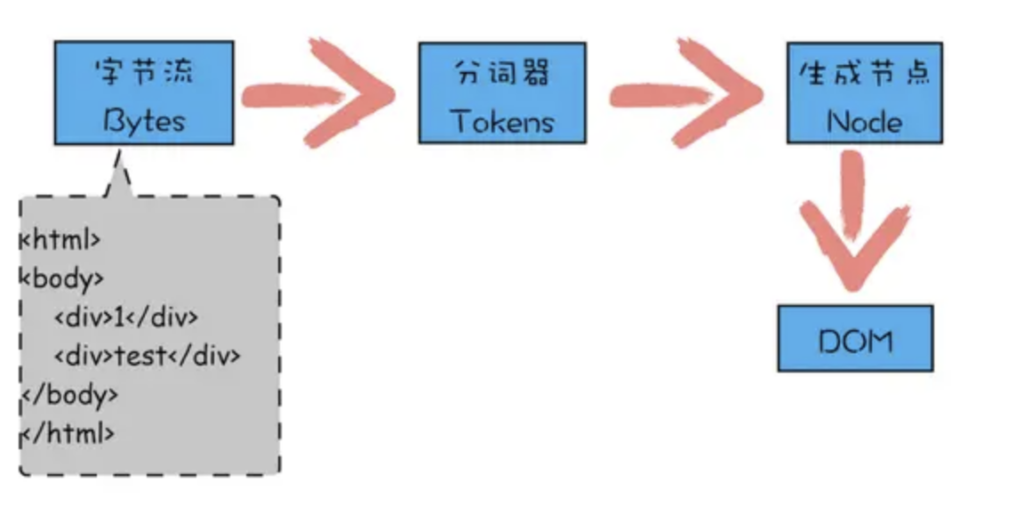
生成 Token 的示意图

Token,分为 Tag Token 和文本 Token,Tag Token 又分 StartTag 和 EndTag。
每个环境都有对应的处理类
- 词法分析 HTMLTokenizer 类
- 词语验证 XSSAuditor 类
- 从词语到节点 HTMLDocumentParser 类、 HTMLTreeBuilder 类
- 从节点到 DOM 树 HTMLConstructionSite 类
构建CSSOM树
- CSSOM树的构建过程与DOM树类似,都是从字符串转成Token对象再创建对应的节点对象
- CSS解析时通过递归去获得每个元素的全部样式
其他过程
- 构建DOM树过程中如果遇到script标签,会去加载JS代码,如未使用async和defer,则会等到JS代码解析执行完成才继续
- 浏览器也会同时去构建一个适用于无障碍模式的Accessibility的DOM树
页面渲染
构建渲染树
- 从 DOM 树根节点开始遍历其每个子节点,找到每个节点对应的CSS样式规则并应用
- 不可见的节点在遍历中会被跳过
布局
- 当渲染树构建完成后,从根节点开始遍历,计算每个节点的宽高、位置等信息
- 第一次确定节点的宽高和位置信息称为布局,后面的每一次变化都称为回流
- 回流会重新计算节点位置信息,开销较大,且回流一定会触发重绘
绘制
- 绘制过程将前面布局计算好的节点绘制在浏览器窗口
- 当元素的任何属性发生变化时,都会进行“重绘”操作来更新元素
浏览器缓存
缓存是指代理服务器或客户端本地磁盘内保存的资源副本,利用缓存可减少对源服务器的访问,节省通信流量和通信时间。
HTTP缓存机制
利用HTTP响应头将所请求的资源在浏览器中进行缓存。
优点
- 减少了冗余的数据(重复资源)传输,节省了网费
- 减少了服务器的负担(开销),大大提升了网站的性能
- 加快了(提高)客户端加载网页的速度
浏览器缓存的分类
- 协商缓存
- 强缓存
浏览器在第一次请求发生后,再次请求时:
浏览器会先获取该资源缓存的 header 信息,根据其中的 expires 和 cahe-control 判断是否命中强缓存,若命中则直接从缓存中获取资源,本次请求不会与服务器进行通信
如果没有命中强缓存,浏览器会发送请求到服务器,该请求会携带第一次请求返回的有关缓存的header 字段信息(Last-Modified / IF-Modified-Since、Etag / IF-None-Match),由服务器根据请求中的相关 header 信息来对比结果是否命中协商缓存,若命中,则服务器返回新的响应header信息更新缓存中的对应header信息,但是并不返回资源内容,它会告知浏览器可以直接从缓存获取
均未命中则返回最新的资源内容
强缓存
强缓存指的是在缓存时间内不会向服务器发起请求,只有过期之后才会向服务器发起请求。
强缓存分为 Expires、cache-control 两种
Expires
该字段是http1.0 时的规范,用于表示资源的过期时间的请求头字段,它的值为一个绝对时间的GMT格式时间字符串,是由服务器端返回的。
浏览器第一次请求服务端资源时,响应头会携带 Expires 信息,标识资源过期时间,下次请求这个资源时会根据上次的 Expires 字段判断是否使用缓存资源。 expires 是根据本地时间来判断的,假设客户端和服务器时间不同,会导致缓存命中误差,且不会判断资源是否变更。
Cache-Control
Cache-Control 是 http1.1 时出现的 header 信息,主要是利用该字段的 max-age 值来进行判断,它是一个相对时间,例如,Cache-Control: max-age=3600,代表着资源的有效期是3600秒。
常用的设置值
max-age
缓存失效相对时间,单位为秒,值为3600,表示(当前时间+3600秒)内不与服务器请求新的数据资源
s-maxage
和max-age一样,但这个是设定代理服务器的缓存时间
no-cache
储存在本地缓存区中,只是在与原始服务器进行新鲜度再验证之前,缓存不能将其提供给客户端使用
no-store
不缓存任何数据
public
所有内容都将被缓存(客户端和代理服务器都可缓存)
private
内容只缓存到私有缓存中(仅客户端可以缓存,代理服务器不可缓存)
only-if-cached
用户只接受中间缓存服务器的资源
Cache-Control与Expires可以在服务端配置同时启用,同时启用的时候Cache-Control优先级高。
协商缓存
协商缓存都会向服务器发送请求,判断缓存数据是否过期,过期的话会返回新的内容,没有过期则使用本地的缓存数据。对于协商缓存主要利用两个字段:Last-Modify、Etag。
强缓存都是由本地浏览器确定是否使用缓存,当浏览器没有命中强缓存就会向服务器发送请求,验证协商缓存是否命中,如果缓存命中则返回304状态码,否则返回新的资源数据。
请求头字段含义
Last-modified
服务器返回给浏览器的资源最近修改时间
if-modified-since
浏览器请求服务端携带的资源最近修改时间
ETag
是一个文件的唯一标识符,当资源发生变化时这个ETag就会发生变化。弥补了上面 last-modified 可能出现文件内容没有变化,但是last-modified发生了变化出现重新向服务器请求资源的情况,也由服务器返回
if-none-match
浏览器请求服务端时带上的字段,值是上次服务器返回的ETag
浏览器请求服务端资源时会携带If-Modified-Since 和 If-None-Match 两个请求头,服务端根据这两个头判断资源是否失效,若未失效则返回给浏览器304,让浏览器从缓存中读取文件。
浏览器请求流程图
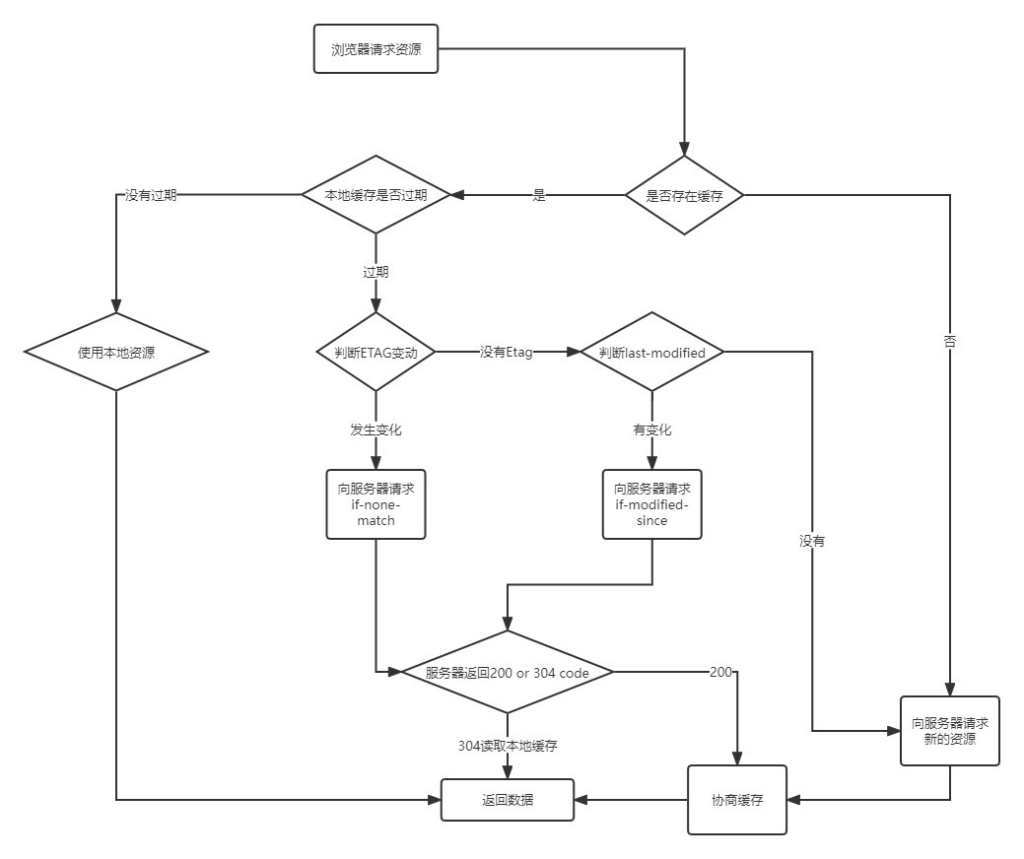
Last-Modified与ETag是可以一起使用的,服务器会优先验证ETag,一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304。
强缓存与协商缓存的区别
| 缓存类型 | 获取资源形式 | 状态码 | 发送请求到服务器 |
|---|---|---|---|
| 强缓存 | 从缓存取 | 200(from cache) | 否,直接从缓存取 |
| 协商缓存 | 从缓存取 | 304(Not Modified) | 否,通过服务器来告知缓存是否可用 |
浏览器内核
- 浏览器内核包含渲染引擎和JS引擎两部分
- 渲染引擎负责读取页面内容(XML、图片、CSS等)并处理渲染逻辑,最终展示在视窗内
- JS引擎负责解析和执行JS代码,处理JS中的事件, 实现页面的动态交互